Retours sur Elastic{ON} Tour Paris 2017
20 février 2018
Après un tour des plus grandes villes du monde en 2017 : Los Angeles, New York, Toronto, Seoul, Tokyo et Munich, l’Elastic{ON} Tour débarque enfin à Paris pour une ouverture du bal de l’année 2018, avec une foule de nouveaux produits à proposer et de nouvelles versions pleines de fonctionnalités innovantes et intéressantes. Et la #KaliopTeam était aux premiers rangs pour apprendre des créateurs et utilisateurs de l’Elastic Stack.
Qu’est-ce que l’Elastic{ON} Tour ?
L’Elastic{ON}Tour est un événement très attendu par toute la communauté des data scientists, gestionnaires de bases de données et autres profils dans le monde du big data qui sont fans des produits opensource que propose l’équipe Elastic.
Pour ceux qui ne connaissent pas encore la stack Elastic, il s’agit d’une suite de produits conçus pour l’ingestion, le traitement et la visualisation de données en open source.
- Logstash, le pipeline spécialisé dans l’ingestion de tous types de données
- Elasticsearch, le SGBD (Sytème de Gestion de Bases de Données)
- Kibana, pour la visualisation
Et les autres produits plus récents :
- Beats, la plateforme regroupant des solutions légères de transfert qui envoient des données provenant de toutes vos machines vers Logstash et Elasticsearch
- X-pack, pour le monitoring, l’alerting, le reporting, la sécurité ainsi que de nouvelles fonctionnalités de graphes
- Et bien entendu une solution Cloud pour héberger tout ça : Elastic Cloud
Après une présentation faite par Shay Banon, Founder & CEO, des nouveaux produits seront prochainement proposés tels que Swiftype ou APM.Adrien Grand Software Engineer chez Elastic depuis 2014 a pris le relais en faisant un dive dans la version 6.x d’Elasticsearch : Cross-cluster search, Ingest Node, Rollover API, Shrink API, Field collapsing, Unified highlighter…
Tant de nouvelles fonctionnalités qui feront encore plus aimer Elasticsearch.
Initialement basé sur Apache Lucene pour le traitement de données full text, E.S. s’adapte aujourd’hui à la demande de ses utilisateurs en traitant désormais les données numériques telles que les adresses IP, les dates, les logs… Rien de mieux pour les community manager qui souhaitent mieux maîtriser les données de leurs réseaux sociaux.
Se sont succédés sur la scène de l’elastic{ON}Tour plusieurs intervenants interne à Elastic pour présenter les nouvelles fonctionnalités de Kibana et mêmes externes.
Les différents points abordés
Ingestion de Données avec Logstash
Logstash, ce puissant pipeline que David Pilato, Evangelist chez Elastic a présenté. Il nous a parlé du monde de l’ingestion de données avec Logstash 5.x qui inclut de nouvelles fonctionnalités telles que le « dead letter« , « persistent queues« , « Grok Debugger » et les « nouvelles API de monitoring« . Puis a présenté les nouveaux agents légers pour le transfert de données : Heartbeat et Metricbeat.
Deep Dive in Kibana
Catherine Johnson, Director of Solution Architecture chez Elastic, a présenté un aperçu des nouvelles visualisations et mises à jours de Kibana dont Time Series Visual Builder, heatmaps, Timelion, tag clouds, Watcher UI, et les alertes sur les clusters.
A travers l’outil X-Pack, l’équipe Elastic propose désormais du Machine Learning

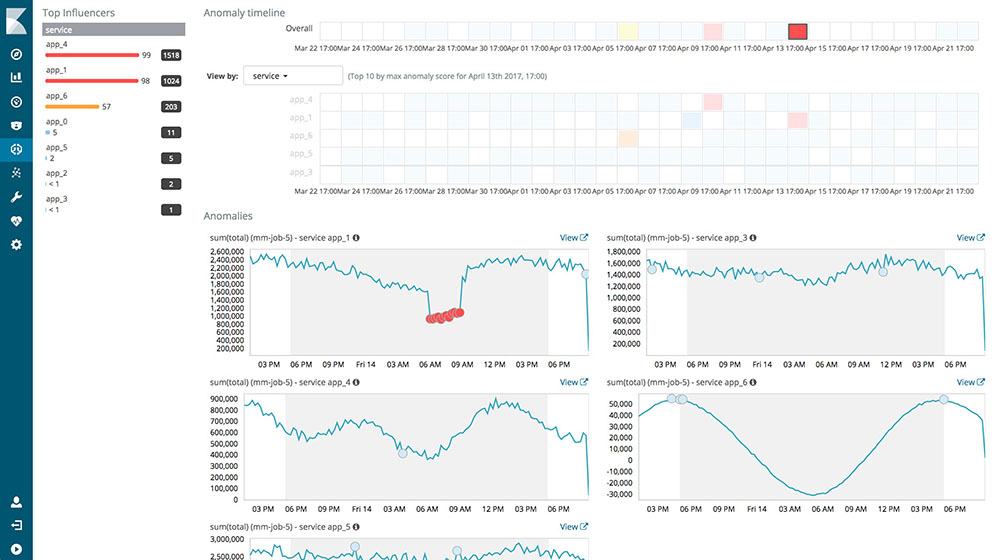
Bahaaldine Azarmi, Solution Architect Manager chez Elastic a exposé un exemple concret de l’utilisation du machine learning avec Kibana. Lancée officiellement dans la version 5.5, machine learning (ML) vous permet de tirer parti des données automatiquement. Cet outil, à travers de la prédiction ou de la projection, permet notamment de détecter les anomalies au sein des données.
Orchestration de Clusters Elasticsearch avec Elastic Cloud Enterprise
Sylvain Wallez, Software Engineer chez Elastic, nous a montré comm déployer et gérer des clusters Elasticsearch sécurisés à l’échelle et sur l’infrastructure de notre choix en utilisant Elastic Cloud Enterprise (ECE), en toute simplicité.
Une conférence très enrichissante et complète sur toute la panoplie de produits dont ont besoin de bons data scientists et de bons social media manager.
Le Machine Learning au cœur des nouveautés depuis la 5.5:
Avec l’avènement du cloud il est devenu très important de bien dimensionner les serveurs, d’anticiper la charge, de redimensionner le serveur en fonction de modèle de charge préétabli, pour économiser en coûteuses ressources.
Prenons par exemple ce modèle : admettons qu’ils gèrent les jours de la semaine, que le jeudi soit le jour où vous avez le moins de visites (selon votre modèle), et que ce même jeudi soit la veille de BlackFriday. Vous n’aviez pas anticipé la hausse de charge : votre serveur se retrouve donc incapable de traiter autant de demandes, et vous n’êtes notifiés qu’une fois votre serveur inaccessible.
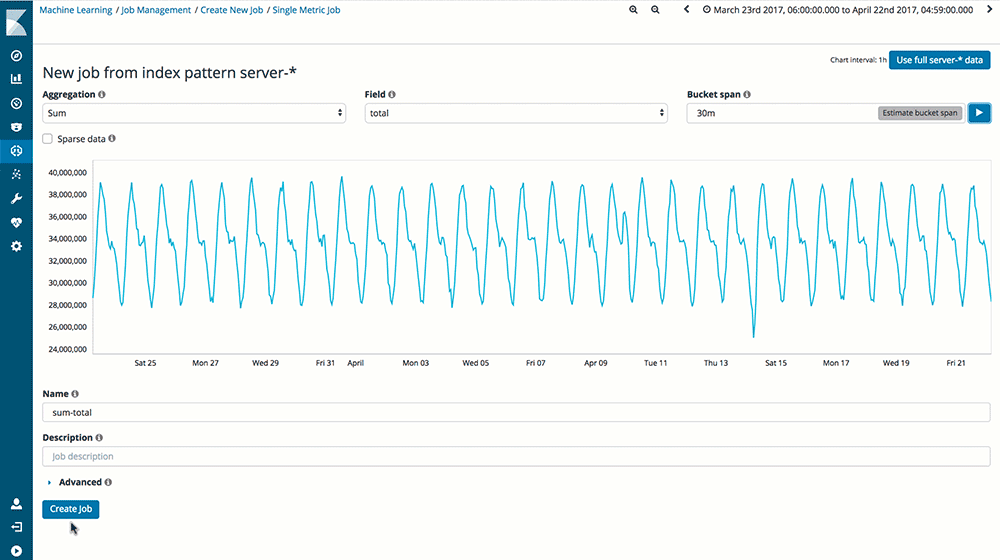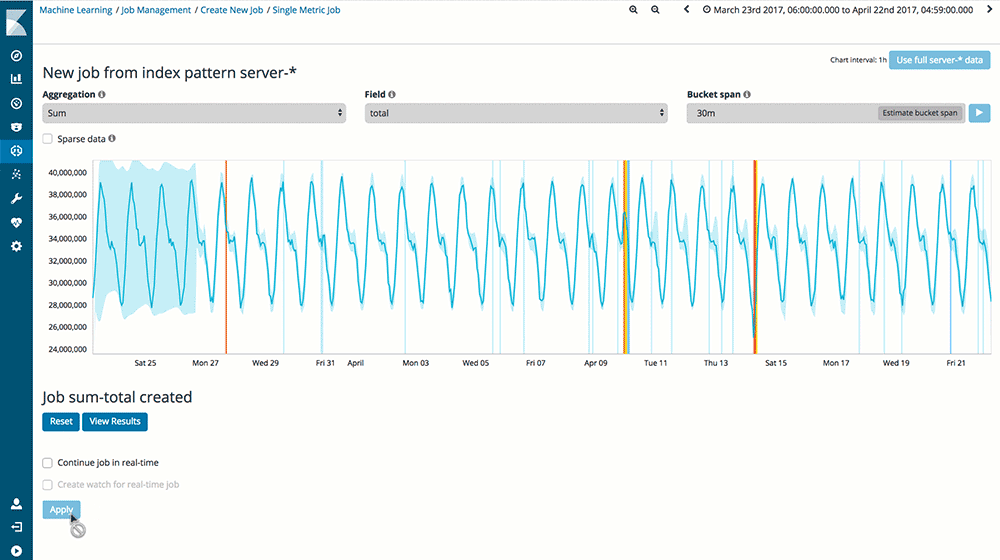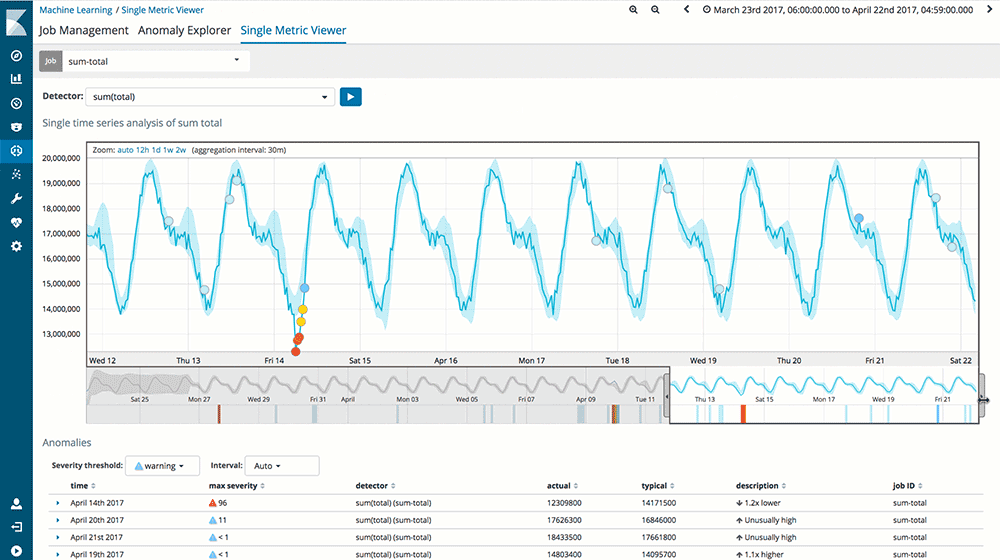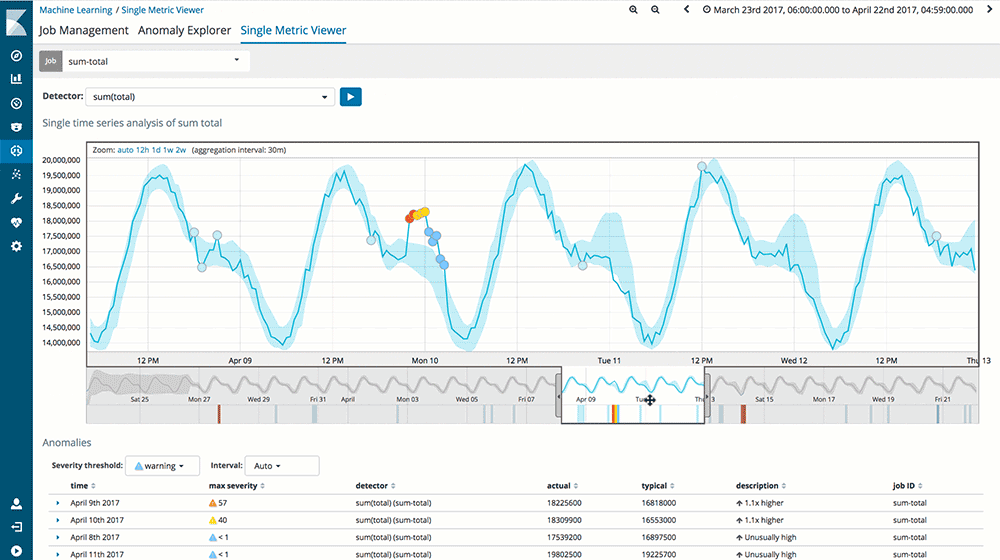
Source : Elastic.co
Le ML quant à lui anticipera. En temps normal, il ne fera pas mieux que le modèle cependant au premier signe de déviation il vous permettra d’ajuster à la hausse comme à la baisse les ressources de vos serveurs, voire de souligner un problème applicatif, qui ne permet plus à vos clients une utilisation optimale de vos applications.
On alerte aussi souvent sur la hausse mais comment alerter sur l’absence ou la baisse de données par rapport à un jour de charge ?
C’est un des cas où la data brille par son absence, qui rend l’analyse/l’alerte par l’anomalie cruciale.
Et ce n’est qu’un exemple d’utilisation de ce Machine Learning et de la Business Intelligence. Sa vrai force est d’identifier des anomalies, des déviations de par lui-même mais aussi d’offrir une projection crédible et de plus en plus fine en fonction des volumes de données analysées et de la distance temporelle de la projection.
Ce qui bluffe sur cette fonctionnalité, c’est que vous ne dirigez plus vos analyses. C’est le Machine Learning qui vous fournit des anomalies et des corrélations entre l’ensemble de vos données visualisées ou non.
Un gain de temps, une aide, un doigt pointé toujours au bon endroit sur votre cœur de métier. Mais aussi : adapter le Machine Learning à tous les domaines de la Big Data.
Source : Elastic.co
Data Lake as a Service
Les présentations qui ont suivi sont des “proof of work”, présentés par des grands des acteurs de l’industrie ou du tertiaire, comme Kamélia Benchekroun, Responsable Data Lake IT Squad chez Renault.
Il y a pas à dire ça rend confiant de voir que les méthodes et les outils que l’on déploie à nos petites échelles, tiennent la charge sur des infrastructures aussi larges que l’ensemble des usines du Groupe Renault.
Non seulement ces retours sont riches en expérience mais ils confirment aussi l’échec de la complexification quand on souhaite déployer des infrastructures complexes ainsi que la nuisance du modèle unique dans des business pluriels.
Construire des PaaS pour permettre au plus grand nombre d’exploiter le Big Data étaitl’objectif de Kamélia Benchekroun et ses équipes.
L’objectif n’a pu être atteint que par la mise en place d’un data lake self-service, où l’utilisateur final (manager par exemple pour la BI) exploite lui-même la donnée brute fournie par le Data Lake.
Un avantage, un gain de temps énorme pour ses équipes qui passaient des temps infinis à comprendre le métier cible avant de pouvoir réaliser des visualisations fidèles.
Grâce à ces méthodes, ses équipes peuvent maintenant se concentrer sur la richesse du contenus du Data Lake, et pourquoi pas envisager de se rapprocher des 100% de données informatisées, un vrai atout pour le business.
Bref ! Vous l’aurez compris, malgré un format moins primeur que les grosses conférences américaines de l’éditeur, c’est toujours un plaisir de rencontrer la communauté francophone et de venir pour parler aux équipes, pour inspirer et concrétiser vos projets ElasticSearch les plus novateurs.
Merci à Florent et Meriem pour cet article.

Commentaires
